The Thermodynamics of Collapse
Why Brute-Force AI Is Dead
Scaling Laws have hit a physical wall. Edge AI is cannibalizing the cloud model. Tech Shadow Banking funded infrastructure with collateral depreciating 70% in 18 months. All while Wall Street applauds the CAPEX.

The Illusion of Scale
The thesis is uncomfortable, but the data confirms it: the market has valued Artificial Intelligence as if it were a resource with infinite increasing returns — as if scale produced intelligence linearly, forever. It does not. "Brute-force" AI — the kind that requires $100B in CAPEX, gigawatts of electricity, and oceans of data — has hit a wall. A physical, thermodynamic, and mathematical wall that no Oracle press release can dissolve.
While Wall Street applauded the latest Microsoft and Oracle CAPEX announcements, an engineer in Taipei was loading Llama-3 on a $1,200 gaming laptop and getting responses in 40 milliseconds. No cloud. No monthly subscription. No small-city electricity bill. Just a chip designed to do exactly that task — and do it better, cheaper, and faster than any Silicon Valley API.
This is not anecdotal. It is the precise manifestation of a structural trend with three dimensions: the exhaustion of Scaling Laws, the Efficient Silicon revolution, and the latent financial risk from the Shadow Banking that funded the party. We analyze each one.
"When a 3-watt chip executes what previously required a $100M Data Center, the question is not whether the hyperscaler business model will change. The question is when the market will stop ignoring it."
📚 Definition: What Are the Scaling Laws?
Scaling Laws are the empirical principle observed by OpenAI (Kaplan et al., 2020) stating that a language model's performance improves predictably when three variables are increased simultaneously: number of parameters, training data volume, and compute power. The relationship follows a power law — meaning doubling compute produces constant and quantifiable improvements in model capabilities.
The market extrapolated this curve to infinity. If GPT-3 (175B parameters) was exponentially better than GPT-2 (1.5B), then GPT-5 and its successors would be exponentially better than GPT-4. The resulting narrative was seductively simple: more CAPEX = more intelligence = more market value. This equation fueled an unprecedented infrastructure valuation bubble.
Limit 1: Requires quality data — and the available human text corpus is running out
Limit 2: Returns are no longer linear at the current frontier — the jump from 1T to 10T parameters disappoints
2024-2025 Shift: Industrial focus shifts from Training to Efficient Inference (RAG, distillation, pruning)
ACT I: The Glass Ceiling of the Scaling Laws
§1 The Fuel Exhaustion: Data Exhaustion and Digital Inbreeding
The premise of massive training is simple: expose the model to enough quality human text and it will learn to model language and reasoning. The premise has a structural problem: quality human text is a finite resource. By mid-2024, the main AI labs had ingested practically all available corpus — books, academic papers, source code, indexed websites, forum conversations. The internet, insofar as LLM training is concerned, is finished.
The industry's response was to resort to synthetic data: training models with outputs generated by other models. The logic seemed impeccable — if GPT-4 generates high-quality text, that text can serve to train GPT-5. But this solution has a name in biology: inbreeding. And in biology as in data, inbreeding amplifies defects and erodes genetic diversity — in this case, cognitive diversity.
Researchers have observed the phenomenon they call "model collapse": when models are trained on synthetic data generated by previous models, statistical distributions progressively concentrate around the most common modes, eliminating the variance that makes a model intelligent. The result is a system that increasingly knows how to better answer what it already knows how to answer — and worse at everything else. Digital inbreeding is here.
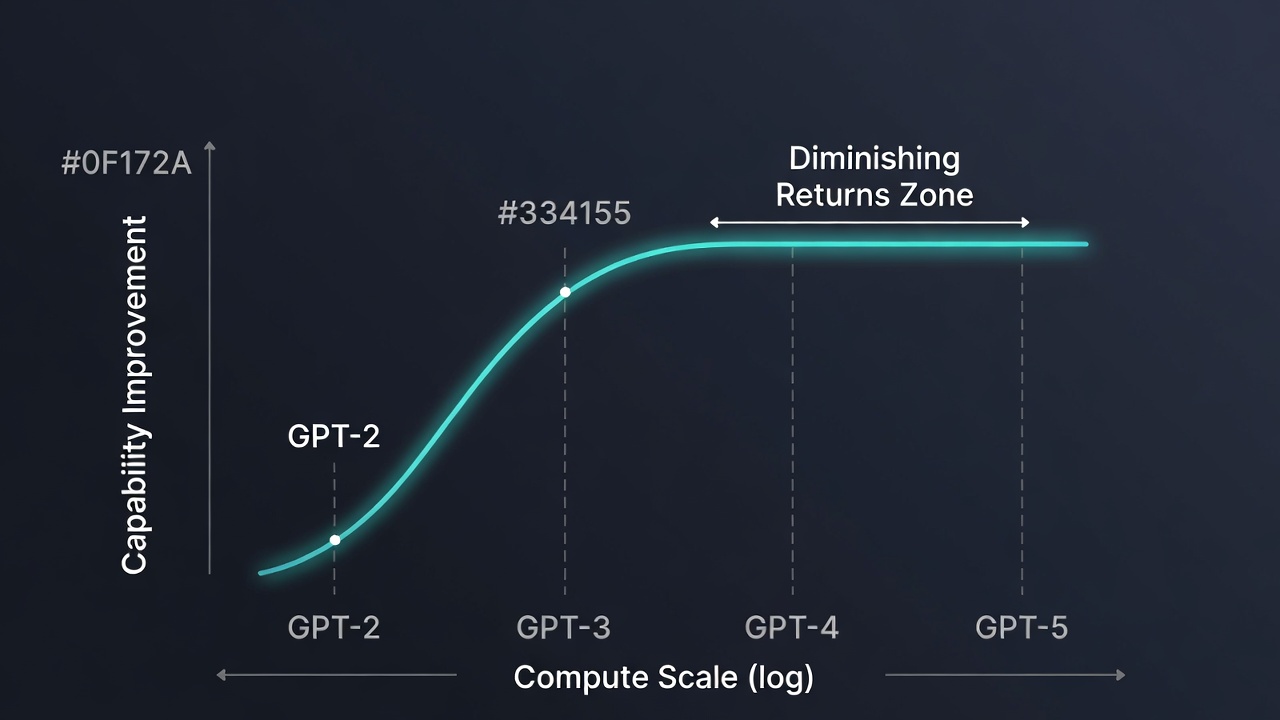
§2 Diminishing Returns: The Physics of Artificial Intelligence
The jump from GPT-2 to GPT-3 was qualitatively revolutionary. The jump from GPT-3 to GPT-4 was significant. The jump from GPT-4 to GPT-4-Turbo was marginal in capabilities, but the compute bill continued growing exponentially. This is exactly what diminishing returns predict: each additional order of magnitude in parameters or compute produces less observable improvement per dollar invested.
Institutional treasury desks that allocated capital to AI infrastructure in 2022-2023 did so based on continuous improvement projections that assumed constant returns. Those projections are incorrect. Models are improving, yes — but at a marginal cost that no longer justifies the extrapolation supporting current valuations.
§3 The Paradigm Shift: From the Training Era to the Efficient Inference Era
The AI market is undergoing a transition that infrastructure investors have not fully discounted: the focus is shifting from Training (training massive models from scratch) to Efficient Inference (running already-trained models as cheaply and quickly as possible). This transition has radical implications for who wins and who loses.
In the Training era, NVIDIA dominated because its GPUs were the best general-purpose hardware for massive parallel matrix operations. In the Efficient Inference era, the terrain favors specialized chips — ASICs designed to execute a specific type of workload with maximum energy efficiency. The world NVIDIA sold its GPUs into is not the world that is coming.
"Going from 1 trillion to 10 trillion parameters doesn't produce 10x more intelligence. It produces 10x the electricity bill."
📚 Definition: ASIC vs GPU — The Scalpel vs the Swiss Army Knife
A GPU (Graphics Processing Unit) is, by design, a general-purpose processor optimized for parallel matrix operations. NVIDIA popularized them for AI because they offer maximum flexibility: they work for training, inference, graphics, and scientific computing. They are the Swiss army knife of computing. Entry price: $30,000–$40,000 per unit (H100). Power consumption: ~700W per unit.
An ASIC (Application-Specific Integrated Circuit) is the opposite: a chip designed for a single task with maximum efficiency. Inference ASICs — Groq's LPU, Google's TPU, the NPUs integrated in high-end smartphones — execute already-trained models at speeds and energy efficiencies no GPU can match. The advantage is not marginal: it can be 10-100x in energy efficiency.
GPU: Flexible, expensive, energy-hungry — ideal for Training. Dominates the current market.
ASIC: Specialized, efficient, low-cost — ideal for Inference. Dominates the future market.
The CAPEX Problem: The $100B was invested in GPUs for a world where Inference migrates to ASICs.
ACT II: The Efficient Silicon Rebellion
§1 The Scalpel's Victory over the Swiss Army Knife
NVIDIA built its monopoly on a valid premise: in the era of massive Training, flexibility was more valuable than specialization. When you don't know exactly what model architecture you'll train, you need hardware that works for everything. That was the market from 2016-2023.
The 2024-2028 market is different. The Transformer architecture is consolidated. Production models are well defined. 95% of AI compute in production is not Training but Inference: running an already-trained model to answer a user query. For that task, the general-purpose GPU is the wrong instrument — like using a hammer for surgery.
Companies like Groq (LPU — Language Processing Unit), Cerebras (wafer-scale chips), SambaNova, and dozens of specialized silicon startups are building the scalpel. Their chips execute inference on LLMs at single-digit millisecond latencies with energy consumption that makes the H100 look like an industrial furnace. Institutional investors know this. Valuations haven't fully reflected it yet.
The Scalpel Doesn't Replace the Hammer — It Makes It Obsolete for the Tasks That Matter
The bullish thesis on NVIDIA assumes the world will always need GPUs because Training will always require general-purpose hardware. What it doesn't discount is that 95% of AI compute in production is Inference, not Training. And for Inference, the ASIC scalpel always beats the GPU hammer — in latency, cost per token, and energy consumption. NVIDIA investors are betting on the hammer in a world filling up with scalpels.
§2 Edge AI: The Transition Nobody Wants to See
The cloud AI business model was built on a technological premise: that capable models required massive, centralized hardware. That premise was true in 2022. It is not in 2025. Small, distilled models — Phi-3 (Microsoft), Llama 3 (Meta), Mistral 7B, Gemma (Google) — are demonstrating that 80% of the enterprise use cases the market imagined as "exclusive domain of massive LLMs" can be resolved with 3-8B parameter models running on local devices.
A modern smartphone with an integrated NPU — the iPhone 16 Pro, Samsung Galaxy S25, or any flagship with Snapdragon 8 Elite — can run language models with latencies under 50ms, without internet dependency, without per-query cost, and without ceding data to third-party servers. If that device is already in every professional's pocket, what differential value does a monthly cloud API subscription offer for the standard use case?
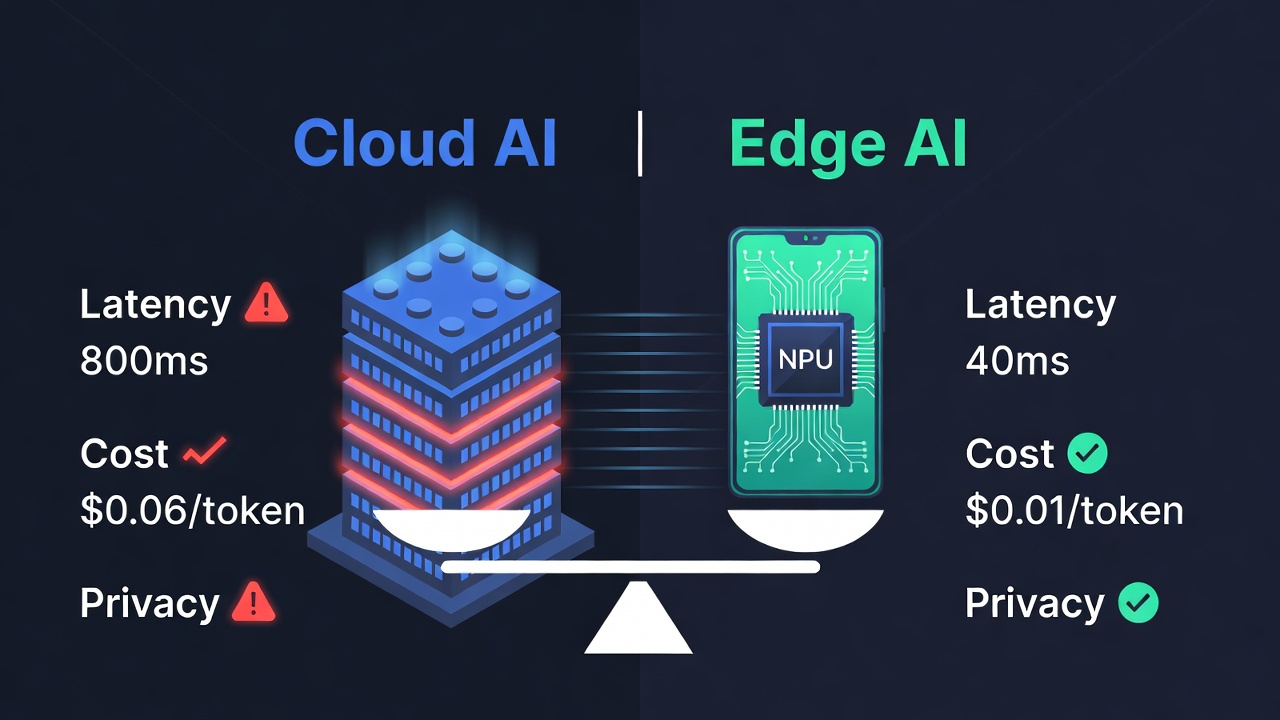
§3 Programmed Obsolescence: Pharaonic Hardware with an Expiry Date
NVIDIA's H100 GPUs, at $30,000–$40,000 per unit, are the central asset of Data Centers built at the peak of the AI investment cycle. They have a standard operational lifespan of 3-5 years — but in technology, functional obsolescence occurs much earlier than physical obsolescence. If the inference market migrates to ASICs with a 10-100x efficiency advantage, the H100s shift from premium assets to secondary market assets in 18-24 months.
The GPU secondary market is already showing stress signals. In 2023, a second-hand H100 traded near list price due to extreme scarcity. In 2025, accumulating supply in the secondary market is starting to pressure prices. This dynamic has direct implications for Act III — because that depreciated hardware is the collateral for much of the technology leverage.
📚 Definition: Tech Shadow Banking
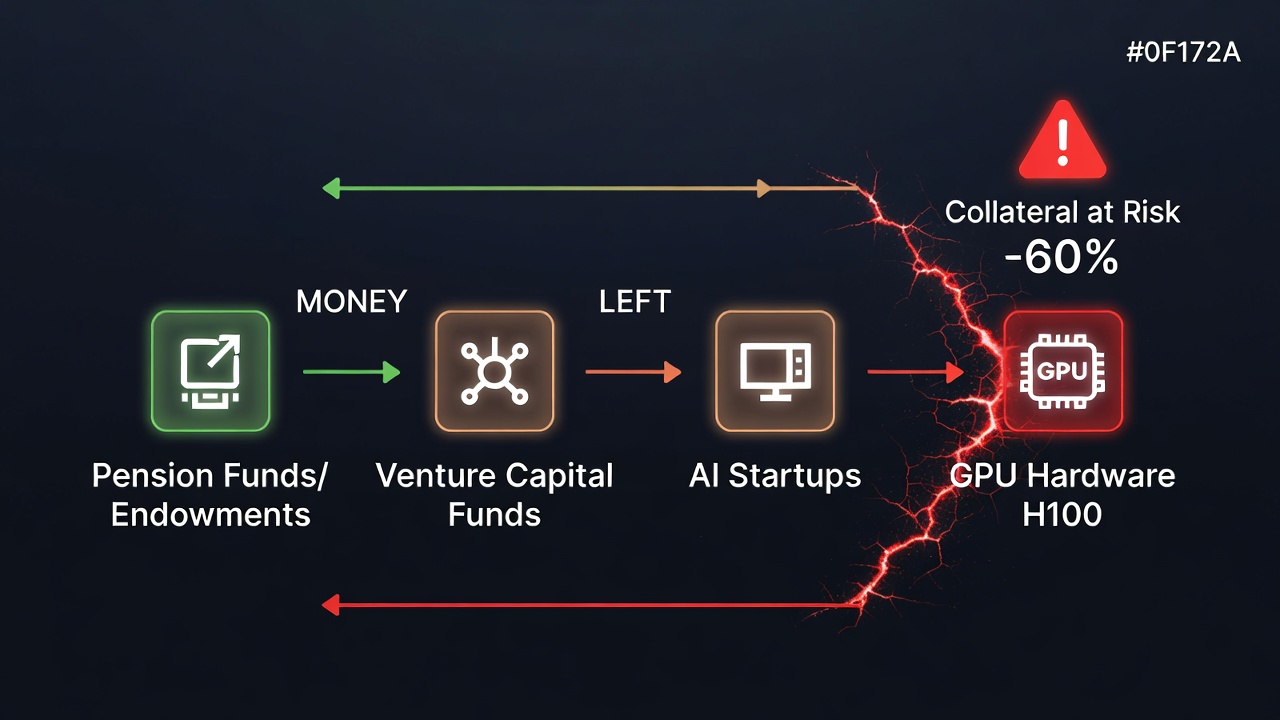
Shadow Banking is the set of financial intermediaries operating outside the regulated banking system: private credit funds, Special Purpose Vehicles (SPVs), venture debt funds and other instruments that provide financing without the prudential supervision of traditional banks.
"Tech Shadow Banking" is the term we use to describe the financing chain connecting pension funds and endowments (as VC LPs) → venture capital funds → AI startups → GPU infrastructure. The chain works while the collateral (GPUs) maintains its value and startups generate enough revenue to service the debt. If either condition fails, the chain breaks — and the risk travels upward.
Risk 1: GPU collateral depreciates 50-70% in 18-24 months under technological transition conditions.
Risk 2: AI startups with 12-18 month runway entering 2026 financing winter.
Precedent: Western Alliance (2023) — tech startup guarantees on depreciated assets triggered contagion.
ACT III: The Tech Shadow Banking Credit Crunch
§1 The Debt Trap: When CAPEX Gets Financed with Leverage
Oracle is not just a software company. In 2024-2025, it transformed into a massive leverage vehicle. To finance its Data Center expansion — contracted with Microsoft, Google, and OpenAI — it issued debt at levels that would have horrified any credit analyst a decade ago. The logic was impeccable in 2023: if hyperscalers sign 10-year contracts, the collateral is solid and cash flow is guaranteed.
The problem is that those contracts are for Training infrastructure — the paradigm that, as we've analyzed in Acts I and II, is being displaced by Efficient Inference at the Edge. A 10-year contract for services the counterparty can substitute with cheaper internal infrastructure is not the collateral it appears to be. The credit analysts who modeled these cash flows in 2023 had not incorporated the risk of accelerated technological obsolescence.
"The collateral of tech Shadow Banking is not Treasury bonds. It is GPUs worth half of yesterday's price."
§2 The Weak Link: Shadow Banking with GPU Collateral
The major hyperscalers — Microsoft and Amazon — can weather the storm. They have diversified cash flows, capital markets access, and the scale to pivot toward new paradigms. The weak link is not at the top of the chain. It is in the middle: the private credit funds and shadow banking that financed the AI startup explosion with GPU-collateralized loans.
The pattern is familiar. In 2022-2023, Silicon Valley Bank held on its balance sheet guarantees from tech startups that had purchased depreciated assets. The risk mechanics are the same in 2025-2026, with GPUs instead of real estate. The regional banks and venture debt funds that financed the AI investment cycle have a credit book whose collateral could lose 60% of its secondary market value in 24 months.
§3 The Snowball of Disillusionment: The Collapse Sequence
Financial narrative collapses always follow a predictable sequence, even if their timing is unpredictable. In the AI case, the logical sequence is: first, benchmark metrics from new massive models disappoint versus expectations (already happening with GPT-4.5 and competitors). Second, generative AI startup valuations adjust — those that promised 80% margins discover that inference costs erode them.
Third, VC fund LPs reduce commitments in the AI sector. Fourth, short-runway startups fail to raise new rounds. Fifth, they must liquidate assets — GPUs first — in already saturated secondary markets. Sixth, secondary market prices collapse. Seventh, shadow banking collateral loses value, generating cascading margin calls. We are not predicting this will happen. We are documenting that the mechanics exist.
The Three Dimensions of Risk
1. Model Risk
Scaling Laws · Data Exhaustion
Scaling Laws have hit the Data Exhaustion wall. Synthetic data produces digital inbreeding. Returns are diminishing. The market has not discounted that the next massive model may not justify the CAPEX.
2. Hardware Risk
ASIC · Edge AI · Obsolescencia
ASICs and local NPUs are cannibalizing the Inference market. Distilled 7B-parameter models solve 80% of use cases. H100s at $35,000/unit become secondary market assets in 24 months.
3. Financial Risk
Shadow Banking · Colateral GPU · Margin Calls
Shadow banking funded the party with GPU collateral. If secondary market prices collapse, risk travels up the chain: private credit funds, regional banks, institutional LPs.
Scenario Map: Implications by Outcome
Uncertainty is not binary — it is a spectrum. These are the three plausible scenarios and their implications for each actor in the chain.
| Scenario | Catalyst | Data Centers / NVIDIA | Financial Risk |
|---|---|---|---|
🟢 Bull |
Edge AI complements Cloud; Training keeps growing; regulation protects hyperscalers |
Moderate CAPEX growth; NVIDIA maintains share with margin pressure |
Contained: shadow banking absorbs the cycle without systemic stress |
🟡 Base |
Edge AI cannibalizes Inference; Cloud specializes in Training and complex cases |
CAPEX peak 2025-2026; Data Centers with <70% utilization; NVIDIA loses 20-30% inference share |
Selective stress: AI startups with tight liquidity; venture debt under pressure |
🔴 Bear |
AI narrative collapse + shadow banking stress + tech recession |
Valuations -50-60%; NVIDIA -40% stock price in 18 months; GPU secondary market collapses |
Credit cascade: margin calls, venture debt fund failures, regional banking contagion |
Conclusion: Plant in the Calm, Harvest in the Chaos
The antifragile operator's strategy does not consist of fleeing technology or going short on everything AI-related. It consists of understanding the structural separation that is occurring: the winning business models will be those that operate at the Edge, with distilled models, minimal energy consumption, and without dependence on third-party Data Center access.
The companies that will sell picks and shovels in the new gold rush will not be those making the biggest picks. They will be those making the most efficient ones. And the financial risk of tech shadow banking — GPU collateral, AI startup loans, second-tier hyperscaler debt — is a risk the market has not fully discounted. The narrative changes before balance sheets acknowledge it.
Key Quote
"The future of Artificial Intelligence does not reside in a supercomputer in a Utah desert. It resides in the chip you already carry in your pocket. The hundred-billion-dollar Data Centers are not the infrastructure of the future: they are the new empty shopping malls of the digital era."
Do You Manage More Than €1M in Assets? Professional Access
Analyzing systemic AI risk — and how to position against it — requires quantitative tools that go far beyond narrative analysis. Our algorithmic systems monitor in real time the stress indicators that precede narrative collapse episodes.
If you are a wealth manager, Family Office, or Institutional with AUM above €1M, discover how our quantitative engineering can protect and grow assets under management in high-volatility environments.
Trading System Club | True Drivers. Structural Alpha. Total Peace of Mind.